
"That I am that same wall; the truth is so."
-- Shakespeare, A Midsummer Night's Dream
Act V, Scene I, Line 160
SQL and higher order functions are completely different. SQL is used to apply functions against collections of data, while higher order functions are used to apply functions against collections of data. Totally different.
I mean have you ever seen both Michael Fogus and Itzik Ben-Gan talked about in the same blog post?!?
I have no idea why people classify declarative programming with SQL as completely different than declarative programming with higher order functions.
I'll use this blog post as a jumping off point to show that they are very similar things.
Let's look at the higher order function of zip. The idea of zip is that you take two or more collections of data and zip them together forming one collection of zipped data. Say you have a collection of greetings ["Hello", "Hi", "Aloha"] and another collection of names ["Mike", "Kelsey", "Jack"]. Given a zip function which takes one string and concats it with ", " and another string you could zip these collections together with that zip function obtaining the following collection ["Hello, Mike", "Hi, Kelsey", "Aloha, Jack"].
Let's look at this in some code.
In the first example we have C# using the zip method on the String class. For the C# zip, we need two collections and a lambda express.
In the second example we have Clojure using the map function. For the Clojure map, we need a function and one or more collections (in this example we have two).
In the third example we have T-SQL using an INNER JOIN along with a CONCAT in the SELECT statement. An INNER JOIN you say? Yes, an INNER JOIN can be thought of as the same thing as a zip. The key is that the key you are matching on (in this case the ROW_NUMBER) needs to match. In the Clojure example we are using a vector which is an associative data structure with the keys being the index values, which is the exact same thing we have in the SQL!
Please play around with the fiddle I created to show this in action.
Showing posts with label SQL Server. Show all posts
Showing posts with label SQL Server. Show all posts
Saturday, April 4, 2015
Sunday, September 28, 2014
How to Get 2 and 4 OR Learning Clojure in Public
"One heart, one bed, two bosoms, and one troth"
-- Shakespeare, A Midsummer Night's Dream
Act II, Scene II, Line 48
I believe in "learning in public" and I've been inspired recently, after watching Uncle Bob's "The Last Programming Language", going to Strange Loop 2014, and the release of The Joy of Clojure 2nd edition, I've decided to learn me a Clojure for great good. I've been going through the 4clojure problems as my morning kata for a few weeks now and I've hit problem #52 earlier in the week.
Intro to Destructuring
Let bindings and function parameter lists support destructuring.
(= [2 4] (let [[a b c d e f g] (range)] __))
The answer is [c e] giving the following expression.
(= [2 4] (let [[a b c d e f g] (range)] [c e]))
which evaluates to true
As I understand it, the way this works is that let binding maps the values from range over a through g which gives the a the value 0, b the value 1, c the value of 2, ..., e the value of 4, and so on. Since we are looking for a vector with the values of 2 and 4, a vector with c and e will give us the [2 4] we are looking for.
How else can we do this?
We could take range, remove the zero value and pipe it through a filter to get just even numbers and then take the 2 and 4.
range -> remove zero -> filter evens -> take first two
In Clojure this would look like this:
-- Shakespeare, A Midsummer Night's Dream
Act II, Scene II, Line 48
I believe in "learning in public" and I've been inspired recently, after watching Uncle Bob's "The Last Programming Language", going to Strange Loop 2014, and the release of The Joy of Clojure 2nd edition, I've decided to learn me a Clojure for great good. I've been going through the 4clojure problems as my morning kata for a few weeks now and I've hit problem #52 earlier in the week.
Intro to Destructuring
Let bindings and function parameter lists support destructuring.
(= [2 4] (let [[a b c d e f g] (range)] __))
The answer is [c e] giving the following expression.
(= [2 4] (let [[a b c d e f g] (range)] [c e]))
which evaluates to true
As I understand it, the way this works is that let binding maps the values from range over a through g which gives the a the value 0, b the value 1, c the value of 2, ..., e the value of 4, and so on. Since we are looking for a vector with the values of 2 and 4, a vector with c and e will give us the [2 4] we are looking for.
How else can we do this?
We could take range, remove the zero value and pipe it through a filter to get just even numbers and then take the 2 and 4.
range -> remove zero -> filter evens -> take first two
In Clojure this would look like this:
(->> (range) (rest) (filter even?) (take 2))
which evaluates to (2 4)
If you want it in a vector you would need to convert the list into a vector which could be done using into, which would look like this:
(->> (range) (rest) (filter even?) (take 2) (into []))
which evaluates to [2 4]
In SQL on SQL Server this would look like this:
DECLARE
@min AS INT = 0
,@max AS INT = 100
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT TOP 2 *
FROM [range]
WHERE num > 0
AND (num % 2) = 0
;
which gives us the result with a projection containing 2 and 4.
We are creating a Tally Table using a CTE (as seen in Vinay Pugalia linked blog post), which will gives us similar functionality as the range in Clojure (similar because Clojure's range is lazy loaded and thus can be infinite). We then filter using the WHERE clause to remove the zero like we do with rest in Clojure, next we filter to just evens using the % operator comparing those results to fine when they equal zero (yes, this not the best way to do this but it is similar). Last we take the first two results by using TOP with 2.
This is very similar to what I blogged about here on doing FizzBuzz in SQL Server.
There you have it, two different solutions in two different languages on two very different platforms to get the first two even numbers greater than zero.
Learning in public can be fun.
Sunday, December 22, 2013
How to Get the Last 5 Rows from SQL Server
"And hear, I think, the very latest counsel"
-- Shakespeare, Henry IV Part 2
Act IV, Scene V, Line 182
Say you have the following need.
Given the following trans table:
CREATE TABLE trans (
id int identity(1,1) not null
,transactionId int not null
,transactionTime datetime2 not null default (sysutcdatetime())
,amount int not null
);
And the following data:
INSERT INTO trans (transactionId, amount) VALUES(1, 100);
INSERT INTO trans (transactionId, amount) VALUES(1, 125);
INSERT INTO trans (transactionId, amount) VALUES(2, 400);
INSERT INTO trans (transactionId, amount) VALUES(4, 25);
INSERT INTO trans (transactionId, amount) VALUES(5, 20);
INSERT INTO trans (transactionId, amount) VALUES(6, 70);
INSERT INTO trans (transactionId, amount) VALUES(7, 100);
INSERT INTO trans (transactionId, amount) VALUES(8, 33);
** Note, done this way to have different transactionTime **
When I query the trans table
Then I want to get the last 5 records in the trans table as indicated by transactionTime
This setup will give us the following.
 http://sqlfiddle.com/#!6/11a33/2
http://sqlfiddle.com/#!6/11a33/2
Luckily, SQL Server 2012 offers a few ways to look at the last few records of a table.
SELECT TOP 5 *
FROM trans
ORDER BY transactionTime DESC
;
By ordering by the transactionTime in descending order we are able to use the TOP filter to obtain the last 5 records.
 http://sqlfiddle.com/#!6/11a33/1
http://sqlfiddle.com/#!6/11a33/1
SELECT *
FROM trans
ORDER BY transactionTime DESC
OFFSET 0 ROWS
FETCH NEXT 5 ROWS ONLY
;
Using the ORDER BY clause, we can use the new to SQL Server 2012 FETCH and OFFSET we are able to follow the ISO SQL 2008 standard for our limiting.
 http://sqlfiddle.com/#!6/11a33/3
http://sqlfiddle.com/#!6/11a33/3
DECLARE @PageSize INT = 5
SELECT *
FROM trans
ORDER BY transactionTime DESC
OFFSET 0 ROWS
FETCH NEXT (SELECT @PageSize) ROWS ONLY
;
In SQL Server 2012, the new FETCH on the ORDER BY clause allows for queries to obtain the number of rows to retrieve!
http://sqlfiddle.com/#!6/11a33/6
SELECT id, transactionId, transactionTime, amount
FROM (
SELECT
ROW_NUMBER() OVER(ORDER BY transactionTime DESC) AS row
,*
FROM trans
) AS r
WHERE r.row <= 5
;
Using the ROW_NUMBER() windowing function, we can create a poor man's FETCH and OFFSET by filtering the row numbers returned to be the number of records we want to obtain.
This idea came from Suprotim Agarwal's blog post on SQL Server Curry.
http://sqlfiddle.com/#!6/11a33/7
"Inform the database whenever you don't need all rows."
SQL Server offers many different ways to get the last 5 records, but one must think of performance. If you have an indexed order by then the DBMS would not even have to perform the sort!
-- Shakespeare, Henry IV Part 2
Act IV, Scene V, Line 182
Intro
Say you have the following need.
Given the following trans table:
CREATE TABLE trans (
id int identity(1,1) not null
,transactionId int not null
,transactionTime datetime2 not null default (sysutcdatetime())
,amount int not null
);
And the following data:
INSERT INTO trans (transactionId, amount) VALUES(1, 100);
INSERT INTO trans (transactionId, amount) VALUES(1, 125);
INSERT INTO trans (transactionId, amount) VALUES(2, 400);
INSERT INTO trans (transactionId, amount) VALUES(4, 25);
INSERT INTO trans (transactionId, amount) VALUES(5, 20);
INSERT INTO trans (transactionId, amount) VALUES(6, 70);
INSERT INTO trans (transactionId, amount) VALUES(7, 100);
INSERT INTO trans (transactionId, amount) VALUES(8, 33);
** Note, done this way to have different transactionTime **
When I query the trans table
Then I want to get the last 5 records in the trans table as indicated by transactionTime
This setup will give us the following.

Luckily, SQL Server 2012 offers a few ways to look at the last few records of a table.
TOP N
SELECT TOP 5 *
FROM trans
ORDER BY transactionTime DESC
;
By ordering by the transactionTime in descending order we are able to use the TOP filter to obtain the last 5 records.

ORDER BY with FETCH and OFFSET
SELECT *
FROM trans
ORDER BY transactionTime DESC
OFFSET 0 ROWS
FETCH NEXT 5 ROWS ONLY
;
Using the ORDER BY clause, we can use the new to SQL Server 2012 FETCH and OFFSET we are able to follow the ISO SQL 2008 standard for our limiting.

Page Size option
DECLARE @PageSize INT = 5
SELECT *
FROM trans
ORDER BY transactionTime DESC
OFFSET 0 ROWS
FETCH NEXT (SELECT @PageSize) ROWS ONLY
;
In SQL Server 2012, the new FETCH on the ORDER BY clause allows for queries to obtain the number of rows to retrieve!
Using ROW_NUMBER
SELECT id, transactionId, transactionTime, amount
FROM (
SELECT
ROW_NUMBER() OVER(ORDER BY transactionTime DESC) AS row
,*
FROM trans
) AS r
WHERE r.row <= 5
;
Using the ROW_NUMBER() windowing function, we can create a poor man's FETCH and OFFSET by filtering the row numbers returned to be the number of records we want to obtain.
This idea came from Suprotim Agarwal's blog post on SQL Server Curry.
Performance
"Inform the database whenever you don't need all rows."
-- Markus Winand, Use the Index Luke - Top-N Rows Queries
SQL Server offers many different ways to get the last 5 records, but one must think of performance. If you have an indexed order by then the DBMS would not even have to perform the sort!
Sunday, December 8, 2013
FizzBuzz - Now in SQL Server
"Yet again? What do you here? Shall we give o'er and
drown? Have you a mind to sink?"
-- Shakespeare, The Tempest
Act I, Scene I, Lines 38-39
The great thing about the FizzBuzz kata is that it is very easy to understand, but has nearly an unlimited number of ways to implement it. I am fan of using the right tool for the job, but I do enjoy stretching things to see what they can and cannot do with the hope of gaining a different point of view. Having said that let us take a look at implementing the FizzBuzz kata in SQL using SQL Server 2012.
The goal of the FizzBuzz kata is to create a list of values which move through a filter with the following rules:
FizzBuzz has one edge case:
An example would be the following:

We see that:
2 => 2
4 => 4
3 => Fizz
9 => Fizz
5 => Buzz
25 => Buzz
15 => FizzBuzz
45 => FizzBuzz
Given that we are going to use SQL Server, the first question is how do we generate a dataset to run through our FizzBuzz? We could create a table with all of the values that we need, but that is not very interesting. Instead we will use a Common Table Expression (CTE) to generate our data.
We'll use a Tally Table as outline by Vinay Pugalia's blog post.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT *
FROM [range]
;
This will generate the number 1 to 20 in a dataset.
 http://sqlfiddle.com/#!6/9cd0c/7
http://sqlfiddle.com/#!6/9cd0c/7
We can generate any dataset starting at @min up to @max using this CTE, not bad.
With our Common Table Expression set up to generate whatever range of numbers we want, we can now focus on the Business Logic of the problem. Since we are looking for particular values to produce a result in some cases it sounds like the perfect job for the CASE statement.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT
CASE
WHEN num % 15 = 0 THEN 'FizzBuzz'
WHEN num % 3 = 0 THEN 'Fizz'
WHEN num % 5 = 0 THEN 'Buzz'
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
;
Gives use the output we would want:
 http://sqlfiddle.com/#!6/9cd0c/12
http://sqlfiddle.com/#!6/9cd0c/12
This gets us what we want, but personally I do not like repeating the logic for divisible by 3 and 5 in the WHEN num % 15 = 0 case.
How about if we join to a set for the Fizz and another set for the Buzz? If we could do that we could use the CONCAT string operation to cover the divisible by 15 edge case.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT
CASE
WHEN CONCAT(fizz.value, buzz.value) <> ''
THEN CONCAT(fizz.value, buzz.value)
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
LEFT OUTER JOIN (
SELECT
num AS id
,'Fizz' AS value
FROM [range] WHERE num % 3 = 0
) AS fizz
ON fizz.id = [range].num
LEFT OUTER JOIN (
SELECT
num AS id
,'Buzz' AS value
FROM [range] WHERE num % 5 = 0
) AS buzz
ON buzz.id = [range].num
;
We create subselects which give us the Fizz and Buzz filters we are looking for. We then use the CONCAT to join a Fizz to a Buzz which will give us FizzBuzz on numbers divisible by both 3 and 5. If we do not have a Fizz or a Buzz the CONCAT will give us '' (empty string), which means we'll want to return the number as a string.
This gives us:
 http://sqlfiddle.com/#!6/9cd0c/20
http://sqlfiddle.com/#!6/9cd0c/20
We can make this a bit more readable using two more CTEs.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
, fizz AS (
SELECT
num AS id
,'Fizz' AS value
FROM [range] WHERE num % 3 = 0
)
, buzz AS (
SELECT
num AS id
,'Buzz' AS value
FROM [range] WHERE num % 5 = 0
)
SELECT
CASE
WHEN CONCAT(fizz.value, buzz.value) <> ''
THEN CONCAT(fizz.value, buzz.value)
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
LEFT OUTER JOIN fizz
ON fizz.id = [range].num
LEFT OUTER JOIN buzz
ON buzz.id = [range].num
;
Which still gives us the same output.
http://sqlfiddle.com/#!6/9cd0c/22
Personally I find the three CTEs a bit cleaner to read and understand, but I understand that not everyone will feel the same way.
There you have it FizzBuzz using SQL Server. You can find the solution on SQL Fiddle (and see all my typing errors to get to it).
"They say there's no such place... as Paradise. Even if you search to the ends of the Earth, there's nothing there. No matter how far you walk, it's always the same road. It just goes on and on. But, in spite of that... Why am I so driven to find it? A voice calls to me... It says, 'Search for Paradise.'"
-- Keiko Nobumoto, Wolf's Rain
Final Lines
drown? Have you a mind to sink?"
-- Shakespeare, The Tempest
Act I, Scene I, Lines 38-39
The great thing about the FizzBuzz kata is that it is very easy to understand, but has nearly an unlimited number of ways to implement it. I am fan of using the right tool for the job, but I do enjoy stretching things to see what they can and cannot do with the hope of gaining a different point of view. Having said that let us take a look at implementing the FizzBuzz kata in SQL using SQL Server 2012.
Overview of FizzBuzz
The goal of the FizzBuzz kata is to create a list of values which move through a filter with the following rules:
- If the number given is divisible by 3 then produce "Fizz"
- If the number given is divisible by 5 then produce "Buzz"
- If the number is not divisible by either 3 or 5 then produce the number given
FizzBuzz has one edge case:
- If the number given is divisible by both 3 and 5 then produce "FizzBuzz"
An example would be the following:

We see that:
2 => 2
4 => 4
3 => Fizz
9 => Fizz
5 => Buzz
25 => Buzz
15 => FizzBuzz
45 => FizzBuzz
How to Generate the Dataset in SQL Server
Given that we are going to use SQL Server, the first question is how do we generate a dataset to run through our FizzBuzz? We could create a table with all of the values that we need, but that is not very interesting. Instead we will use a Common Table Expression (CTE) to generate our data.
We'll use a Tally Table as outline by Vinay Pugalia's blog post.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT *
FROM [range]
;
This will generate the number 1 to 20 in a dataset.

We can generate any dataset starting at @min up to @max using this CTE, not bad.
Setting up the Business Logic
With our Common Table Expression set up to generate whatever range of numbers we want, we can now focus on the Business Logic of the problem. Since we are looking for particular values to produce a result in some cases it sounds like the perfect job for the CASE statement.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT
CASE
WHEN num % 15 = 0 THEN 'FizzBuzz'
WHEN num % 3 = 0 THEN 'Fizz'
WHEN num % 5 = 0 THEN 'Buzz'
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
;
Gives use the output we would want:

This gets us what we want, but personally I do not like repeating the logic for divisible by 3 and 5 in the WHEN num % 15 = 0 case.
How about if we join to a set for the Fizz and another set for the Buzz? If we could do that we could use the CONCAT string operation to cover the divisible by 15 edge case.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
SELECT
CASE
WHEN CONCAT(fizz.value, buzz.value) <> ''
THEN CONCAT(fizz.value, buzz.value)
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
LEFT OUTER JOIN (
SELECT
num AS id
,'Fizz' AS value
FROM [range] WHERE num % 3 = 0
) AS fizz
ON fizz.id = [range].num
LEFT OUTER JOIN (
SELECT
num AS id
,'Buzz' AS value
FROM [range] WHERE num % 5 = 0
) AS buzz
ON buzz.id = [range].num
;
We create subselects which give us the Fizz and Buzz filters we are looking for. We then use the CONCAT to join a Fizz to a Buzz which will give us FizzBuzz on numbers divisible by both 3 and 5. If we do not have a Fizz or a Buzz the CONCAT will give us '' (empty string), which means we'll want to return the number as a string.
This gives us:

We can make this a bit more readable using two more CTEs.
DECLARE
@min AS INT = 1
,@max AS INT = 20
;WITH [range] AS (
SELECT @min AS num
UNION ALL
SELECT num + 1 FROM [range] WHERE num < @max
)
, fizz AS (
SELECT
num AS id
,'Fizz' AS value
FROM [range] WHERE num % 3 = 0
)
, buzz AS (
SELECT
num AS id
,'Buzz' AS value
FROM [range] WHERE num % 5 = 0
)
SELECT
CASE
WHEN CONCAT(fizz.value, buzz.value) <> ''
THEN CONCAT(fizz.value, buzz.value)
ELSE CAST(num AS VARCHAR)
END AS value
FROM [range]
LEFT OUTER JOIN fizz
ON fizz.id = [range].num
LEFT OUTER JOIN buzz
ON buzz.id = [range].num
;
Which still gives us the same output.
Personally I find the three CTEs a bit cleaner to read and understand, but I understand that not everyone will feel the same way.
There you have it FizzBuzz using SQL Server. You can find the solution on SQL Fiddle (and see all my typing errors to get to it).
"They say there's no such place... as Paradise. Even if you search to the ends of the Earth, there's nothing there. No matter how far you walk, it's always the same road. It just goes on and on. But, in spite of that... Why am I so driven to find it? A voice calls to me... It says, 'Search for Paradise.'"
-- Keiko Nobumoto, Wolf's Rain
Final Lines
Saturday, November 23, 2013
On NULL
King James Bible
1 Timothy 6:7
What does it mean for something to be NULL? Even better what is the meaning of meaning? Even more interesting why does no one care?
These are interesting questions, but not really in the realm of a pragmatic programer. How about an easier question, how does NULL work with different operations in different environments? Now this is a question that we can search out an answer for and maybe learn something along the way.
NULL in SQL Server 2012
Databases and NULLs, nothing is more hotly debated (well maybe NoSQL v. RDBS, but I digress). Lets look at how NULL works with subtraction, addition, multiplication, and division in SQL Server 2012.
SELECT '9 - NULL' AS Problem, 9 - NULL AS 'Answer'
UNION ALL
SELECT 'NULL - 9' AS Problem, NULL - 9 AS 'Answer'
UNION ALL
SELECT 'NULL - NULL' AS Problem, NULL - NULL AS 'Answer'
UNION ALL
SELECT '9 + NULL' AS Problem, 9 + NULL AS 'Answer'
UNION ALL
SELECT 'NULL + 9' AS Problem, NULL + 9 AS 'Answer'
UNION ALL
SELECT 'NULL + NULL' AS Problem, NULL + NULL AS 'Answer'
UNION ALL
SELECT '9 * NULL' AS Problem, 9 * NULL AS 'Answer'
UNION ALL
SELECT 'NULL * 9' AS Problem, NULL * 9 AS 'Answer'
UNION ALL
SELECT 'NULL * NULL' AS Problem, NULL * NULL AS 'Answer'
UNION ALL
SELECT '9 / NULL' AS Problem, 9 / NULL AS 'Answer'
UNION ALL
SELECT 'NULL / 9' AS Problem, NULL / 9 AS 'Answer'
UNION ALL
SELECT 'NULL / NULL' AS Problem, NULL / NULL AS 'Answer'
Gives us the following on SQLFiddle.

All NULL, interesting.
NULL in MySQL 5.6.6 m9
How about MySQL? (I do not use MySQL, so I just picked the newest version on SQLFiddle)
After a quick check of the MySQL documentation we see that we can use the exact same syntax to SELECT from no table (FROM DUAL can also be used).
SELECT '9 - NULL' AS Problem, 9 - NULL AS 'Answer'
UNION ALL
SELECT 'NULL - 9' AS Problem, NULL - 9 AS 'Answer'
UNION ALL
SELECT 'NULL - NULL' AS Problem, NULL - NULL AS 'Answer'
UNION ALL
SELECT '9 + NULL' AS Problem, 9 + NULL AS 'Answer'
UNION ALL
SELECT 'NULL + 9' AS Problem, NULL + 9 AS 'Answer'
UNION ALL
SELECT 'NULL + NULL' AS Problem, NULL + NULL AS 'Answer'
UNION ALL
SELECT '9 * NULL' AS Problem, 9 * NULL AS 'Answer'
UNION ALL
SELECT 'NULL * 9' AS Problem, NULL * 9 AS 'Answer'
UNION ALL
SELECT 'NULL * NULL' AS Problem, NULL * NULL AS 'Answer'
UNION ALL
SELECT '9 / NULL' AS Problem, 9 / NULL AS 'Answer'
UNION ALL
SELECT 'NULL / 9' AS Problem, NULL / 9 AS 'Answer'
UNION ALL
SELECT 'NULL / NULL' AS Problem, NULL / NULL AS 'Answer'
Let's see what we get.

Results are exactly the same as SQL Server, everything is NULL.
NULL in SQLite (SQL.js)
How about using NULL in something a bit different, how about running it in SQL.js?
I've never really used SQLite, but a quick look at StackOverflow says that we can continue with our example of SELECT with no table.
SELECT '9 - NULL' AS Problem, 9 - NULL AS 'Answer'
UNION ALL
SELECT 'NULL - 9' AS Problem, NULL - 9 AS 'Answer'
UNION ALL
SELECT 'NULL - NULL' AS Problem, NULL - NULL AS 'Answer'
UNION ALL
SELECT '9 + NULL' AS Problem, 9 + NULL AS 'Answer'
UNION ALL
SELECT 'NULL + 9' AS Problem, NULL + 9 AS 'Answer'
UNION ALL
SELECT 'NULL + NULL' AS Problem, NULL + NULL AS 'Answer'
UNION ALL
SELECT '9 * NULL' AS Problem, 9 * NULL AS 'Answer'
UNION ALL
SELECT 'NULL * 9' AS Problem, NULL * 9 AS 'Answer'
UNION ALL
SELECT 'NULL * NULL' AS Problem, NULL * NULL AS 'Answer'
UNION ALL
SELECT '9 / NULL' AS Problem, 9 / NULL AS 'Answer'
UNION ALL
SELECT 'NULL / 9' AS Problem, NULL / 9 AS 'Answer'
UNION ALL
SELECT 'NULL / NULL' AS Problem, NULL / NULL AS 'Answer'

Interesting, we get nothing, no text, no NULL, nothing. Hmmm, what does this mean? How about another test.
SELECT NULL AS 'value'
UNION ALL
SELECT '' AS 'value'
UNION ALL
SELECT 9 AS 'value'
;
INSERT INTO notNeeded (id)
VALUES(NULL),(8);
SELECT * FROM notNeeded; -- Needed now!
Hmmm, we get the following from SQLFiddle now.

A quick Google search and we find the following blog post which states.
"The .nullvalue command tells the SQLite to show NULL values as NULL. SQLite shows empty strings for NULL values by default"
-- Jan Bodnar, Inserting, updating and deleting data
As I was thinking, so the results are the same as SQL Server and MySQL, just NULL all the way down.
NULL in F#
How about a strongly typed language like F#?
We get the following:
9 - null;;
gives us
9 - null;;
--^
stdin(5,3): error FS0043: The type 'int' does not have 'null' as a proper value
Hmmm, how about this:
null - null;;
gives us
null - null;;
-----^
stdin(3,6): error FS0071: Type constraint mismatch when applying the default type 'int' for a type inference variable. The type 'int' does not have 'null' as a proper value Consider adding further type constraints
No luck, it will not even compile. Looks like strong typing is working.
NULL in JavaScript
How about JavaScript (using node.js 0.10)?
C:\Documents and Settings\Mike Harris>node
> 9 - null
9
> null - 9
-9
> null - null
0
>
JavaScript is built to not "fail" and as such it treats null the same as 0. Hmmm, how about if we divide by null?
> 9 / null
Infinity
> null / 9
0
> null / null
NaN
>
Interesting. Let's look at the other odd values in JavaScript like [], {}, and NaN.
> 9 - []
9
> [] - 9
-9
> [] - []
0
> 9 - {}
NaN
> {} - 9
NaN
> {} - {}
NaN
> NaN - 9
NaN
> 9 - NaN
NaN
> NaN - NaN
NaN
>
How about if we mix them?
> [] - {}
NaN
> {} - []
NaN
> NaN - {}
NaN
> NaN - []
NaN
> {} - NaN
NaN
> [] - NaN
NaN
> [] / {}
NaN
>
Gary Bernhardt did something very similar (but a lot better and funnier) at CodeMash 2012.
"With that harsh, noble, simple nothing"
Saturday, November 16, 2013
Working with Multiple Values in a Column with SQL Server
"Any hard lesson that may do thee good."
-- Shakespeare, Much Ado About Nothing
Act I, Scene I, Line 272
SQL is a good tool when you have large sets of relational records--whether or not these kinds of relationships exist in the real world is not the aim of this post. However, SQL is not very good at normalizing multiple records in a single attribute.
I know, an example would be good right about now.

As we see above Attribute 2 has three different values in it (Value 1, Value 2, and Value 3).
Say we want to do the following.
 We want to take the Order File's Order Records and place the Order ID and others into the Order Table while placing the Order ID and Flags into the Order Flag Table.
We want to take the Order File's Order Records and place the Order ID and others into the Order Table while placing the Order ID and Flags into the Order Flag Table.
Well we have a problem, how are we going to take the Flags and normalize them into the Order Flag Table?
Say the Flags are separated by spaces so Flags looks like this in an Order Record:

How would we do this in SQL? Hmmm, well SQL is not really good at this kind of process so we need to do a kind of hack.
In SQL Server 2012 (should work in 2008 too) we can transform the Flags into XML that looks like this:
Once the data looks like this we can SQL Server's built in XML processing to create a virtual table to obtain the values from.
We can set up a test case using the following a CTE.
Which looks like this in SQL Fiddle:

We see that we have two records: ('HERP DREP CHS XMS', 1) and ('HELLO WORLD', 2).
Now lets take the Flags and transform them using an XML trick.
;WITH cte(value, id) AS (
SELECT *
FROM (
VALUES
('HERP DREP CHS XMS', 1)
,('HELLO WORLD', 2)
) AS x(a, b)
)
SELECT
flags.flag.value('.', 'varchar(50)') AS Flag
,id AS "Order ID"
,ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS "KEY"
FROM (
SELECT
CAST('<flag>' + REPLACE(value, ' ', '</flag><flag>') + '</flag>' AS XML)
,id
FROM cte
) AS f(x, id)
CROSS APPLY f.x.nodes('flag') AS flags(flag)
We now have this in SQL Fiddle.
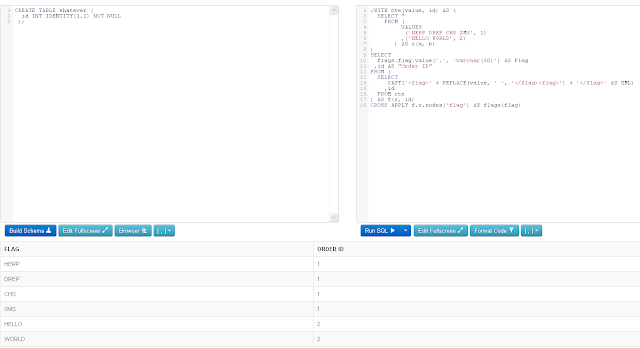 http://sqlfiddle.com/#!6/aed15/2
http://sqlfiddle.com/#!6/aed15/2
This gives us each Flag with its Order ID (Herp with 1, Derp with 1, CHS with 1, XMS with 1, Hello with 2, and World with 2).
This is almost what we want but we need an unique Key for each Flag across all of the records. Now in the ETL tool I was using when I faced this problem this week, it needed an unique Key for each of the Flag records that would come out of the SQL used, even though it would be mapping this unique Key to an Identity column in SQL Server. Yes, this is very dumb but
When tools do dumb things, one must make sure that one does not do dumb things himself.
-- Me, this blog post
With this in mind, let us create an unique Key in a smart way for each Flag record coming out of our SQL hack.
This gives us the following in SQL Fiddle.
 http://sqlfiddle.com/#!6/aed15/3
http://sqlfiddle.com/#!6/aed15/3
Now we have an unique Key!
This gives us each Flag with its Order ID and Key (Herp with 1 and 1, Derp with 1 and 2, CHS with 1 and 3, XMS with 1 and 4, Hello with 2 and 5, and World with 2 and 6).
Nice now we can get back to delivering real value to our customers and not just figuring out tools and strange data.
If you want to see other examples using CTEs and SELECT NULL see these other post by me.
http://comp-phil.blogspot.com/2013/02/the-case-of-not-having-unique-identity.html
http://comp-phil.blogspot.com/2013/02/how-to-remove-duplicate-records-using.html
-- Shakespeare, Much Ado About Nothing
Act I, Scene I, Line 272
SQL is a good tool when you have large sets of relational records--whether or not these kinds of relationships exist in the real world is not the aim of this post. However, SQL is not very good at normalizing multiple records in a single attribute.
I know, an example would be good right about now.

As we see above Attribute 2 has three different values in it (Value 1, Value 2, and Value 3).
Say we want to do the following.

Well we have a problem, how are we going to take the Flags and normalize them into the Order Flag Table?
Say the Flags are separated by spaces so Flags looks like this in an Order Record:

How would we do this in SQL? Hmmm, well SQL is not really good at this kind of process so we need to do a kind of hack.
In SQL Server 2012 (should work in 2008 too) we can transform the Flags into XML that looks like this:
Once the data looks like this we can SQL Server's built in XML processing to create a virtual table to obtain the values from.
We can set up a test case using the following a CTE.
;WITH cte(value, id) AS (
SELECT *
FROM (
VALUES
('HERP DREP CHS XMS', 1)
,('HELLO WORLD', 2)
) AS x(a, b)
)
SELECT *
FROM cte

We see that we have two records: ('HERP DREP CHS XMS', 1) and ('HELLO WORLD', 2).
Now lets take the Flags and transform them using an XML trick.
;WITH cte(value, id) AS (
SELECT *
FROM (
VALUES
('HERP DREP CHS XMS', 1)
,('HELLO WORLD', 2)
) AS x(a, b)
)
SELECT
flags.flag.value('.', 'varchar(50)') AS Flag
,id AS "Order ID"
,ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS "KEY"
FROM (
SELECT
CAST('<flag>' + REPLACE(value, ' ', '</flag><flag>') + '</flag>' AS XML)
,id
FROM cte
) AS f(x, id)
CROSS APPLY f.x.nodes('flag') AS flags(flag)
We now have this in SQL Fiddle.

This gives us each Flag with its Order ID (Herp with 1, Derp with 1, CHS with 1, XMS with 1, Hello with 2, and World with 2).
This is almost what we want but we need an unique Key for each Flag across all of the records. Now in the ETL tool I was using when I faced this problem this week, it needed an unique Key for each of the Flag records that would come out of the SQL used, even though it would be mapping this unique Key to an Identity column in SQL Server. Yes, this is very dumb but
When tools do dumb things, one must make sure that one does not do dumb things himself.
-- Me, this blog post
With this in mind, let us create an unique Key in a smart way for each Flag record coming out of our SQL hack.
This gives us the following in SQL Fiddle.

Now we have an unique Key!
This gives us each Flag with its Order ID and Key (Herp with 1 and 1, Derp with 1 and 2, CHS with 1 and 3, XMS with 1 and 4, Hello with 2 and 5, and World with 2 and 6).
Nice now we can get back to delivering real value to our customers and not just figuring out tools and strange data.
If you want to see other examples using CTEs and SELECT NULL see these other post by me.
http://comp-phil.blogspot.com/2013/02/the-case-of-not-having-unique-identity.html
http://comp-phil.blogspot.com/2013/02/how-to-remove-duplicate-records-using.html
Saturday, August 17, 2013
Learn You Some SQL For Great Good - Unlearn What You Have Learned OR How Select Logically Works (the SELECT clause--OVER Ranking clause)
"The rich ruleth over the poor,
and the borrower is servant to the lender.
He that soweth iniquity shall reap vanity:
and the rod of his anger shall fail."
-- Proverbs 22:7-8
We are still on the SELECT clause.
The easy way to think of the OVER clause is that it is a GROUP BY applied to the data set being SELECTed (note this is not what is actually happening, but it is the easy way to think about it).
Given the following table (or data set) of playwrights:
CREATE TABLE playwrights ( id [int] IDENTITY(1,1) ,name [varchar](100) ,birthYear [int] ,birthEra [char](2));
INSERT INTO playwrights
(name, birthYear, birthEra)
VALUES
('Oscar Wilde', 1854, 'AD')
,('Euripides', 480, 'BC')
,('Aeschylus', 525, 'BC')
,('Sophocles', 497, 'BC')
,('William Shakespeare', 1564, 'AD')
,('Jacopone da Todi', 1230, 'AD')
;
We see that the playwrights have a natural ranking by birthEra and birthYear, so if we wanted to rank them by when they were born we could do something like the following for the BC era playwrights:
SELECT
*
,RANK() OVER (ORDER BY birthYear DESC) AS rank
FROM playwrights
WHERE birthEra = 'BC'
;

(on SQL Fiddle)
Looking at the results we see that the rank returned is ordered by the the birthYear in descending order, for the BC era this is what we want.
Now for AD era we want the birthYear to be ranked in ascending order, like this:
SELECT
*
,RANK() OVER (ORDER BY birthYear ASC) AS rank
FROM playwrights
WHERE birthEra = 'AD'
;

(on SQL Fiddle)
If we want to combine the results into one, we can UNION the two sets and do a RANKing over the results:
SELECT
RANK() OVER (ORDER BY birthEra DESC, year_rank ASC) AS rank
,*
FROM (
SELECT
*
,RANK() OVER (ORDER BY birthYear DESC) AS year_rank
FROM playwrights
WHERE birthEra = 'BC'
UNION ALL
SELECT
*
,RANK() OVER (ORDER BY birthYear ASC) AS year_rank
FROM playwrights
WHERE birthEra = 'AD'
) AS needed_for_sub_select
;

(on SQL Fiddle)
The sub select will allow us to rank each era in the correct way (BC by DESC and AD by ASC). We combine each result from the two sub selects with a UNION ALL, this gives us one big data set which is piped to the outer SELECT statement. Given this big data set we can now do an OVER clause on the UNION of the two sets in the sub select with a RANKing by the birthEra descending (so that BC is before AD) followed by year_rank. This is a fairly clean and readable way to solve the problem (plus it is very fast, more on that later).
and the borrower is servant to the lender.
He that soweth iniquity shall reap vanity:
and the rod of his anger shall fail."
-- Proverbs 22:7-8
RANKing OVER data sets
We are still on the SELECT clause.
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE or WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
The easy way to think of the OVER clause is that it is a GROUP BY applied to the data set being SELECTed (note this is not what is actually happening, but it is the easy way to think about it).
RANKing
Given the following table (or data set) of playwrights:
CREATE TABLE playwrights ( id [int] IDENTITY(1,1) ,name [varchar](100) ,birthYear [int] ,birthEra [char](2));
INSERT INTO playwrights
(name, birthYear, birthEra)
VALUES
('Oscar Wilde', 1854, 'AD')
,('Euripides', 480, 'BC')
,('Aeschylus', 525, 'BC')
,('Sophocles', 497, 'BC')
,('William Shakespeare', 1564, 'AD')
,('Jacopone da Todi', 1230, 'AD')
;
We see that the playwrights have a natural ranking by birthEra and birthYear, so if we wanted to rank them by when they were born we could do something like the following for the BC era playwrights:
SELECT
*
,RANK() OVER (ORDER BY birthYear DESC) AS rank
FROM playwrights
WHERE birthEra = 'BC'
;
(on SQL Fiddle)
Looking at the results we see that the rank returned is ordered by the the birthYear in descending order, for the BC era this is what we want.
Now for AD era we want the birthYear to be ranked in ascending order, like this:
SELECT
*
,RANK() OVER (ORDER BY birthYear ASC) AS rank
FROM playwrights
WHERE birthEra = 'AD'
;
(on SQL Fiddle)
If we want to combine the results into one, we can UNION the two sets and do a RANKing over the results:
SELECT
RANK() OVER (ORDER BY birthEra DESC, year_rank ASC) AS rank
,*
FROM (
SELECT
*
,RANK() OVER (ORDER BY birthYear DESC) AS year_rank
FROM playwrights
WHERE birthEra = 'BC'
UNION ALL
SELECT
*
,RANK() OVER (ORDER BY birthYear ASC) AS year_rank
FROM playwrights
WHERE birthEra = 'AD'
) AS needed_for_sub_select
;
(on SQL Fiddle)
The sub select will allow us to rank each era in the correct way (BC by DESC and AD by ASC). We combine each result from the two sub selects with a UNION ALL, this gives us one big data set which is piped to the outer SELECT statement. Given this big data set we can now do an OVER clause on the UNION of the two sets in the sub select with a RANKing by the birthEra descending (so that BC is before AD) followed by year_rank. This is a fairly clean and readable way to solve the problem (plus it is very fast, more on that later).
Sunday, August 4, 2013
Learn You Some SQL For Great Good - Unlearn What You Have Learned OR How Select Logically Works (the SELECT clause)
"Though thanks to all, must I select from all. The rest
Shall bear the business in some other fight,"
-- Shakespeare, Coriolanus
Act I, Scene VI, Lines 81-82
We are finally on the term SELECT. Yep, this is normally the first thing covered when one learns about SQL, but as you now know SELECT is logically the 8th thing that gets looked at when doing a SELECT SQL query.
A projection is a fancy relational algebra term for something that is very easy to understand. A project can be thought of as a list of things that one wants from a set.
Given the following tables (or data sets):
CREATE TABLE plays (
id [int] IDENTITY(1,1)
,name [varchar](100)
,playwrightId [int]
);
CREATE TABLE playwrights (
id [int] IDENTITY(1,1)
,name [varchar](100)
,birthYear [int]
,birthEra [char](2)
);
We can say I am only interested in the name column (or attribute) of the plays table with the following query.

SELECT name
FROM plays
;
(on SQL Fiddle)
This will limit are results to just the plays in the plays table.
Like wise we can join the two tables together and say which columns (attributes) we want for each.

SELECT
p.name AS play
,w.name AS playwright
FROM plays AS p
INNER JOIN playwrights AS w
ON p.playwrightId = w.id
;
(on SQL Fiddle)
Notice we just do not speak of the things we do not want, SQL is a declarative language (yep, even Forbes think declarative programming is a good thing), this means we describe what we want and not how to do it.
Also notice the AS term, this term allows us to alias things. If we did not have the alias of p and w on the plays and playwrights tables we would not be able to distinguish between the plays' name column and the playwrights' name column or the id on plays and the id on playwrights
SELECT
name AS play
,name AS playwright
FROM plays
INNER JOIN playwrights
ON playwrightId = id
;
(on SQL Fiddle)
We get the following error:
Ambiguous column name 'id'.: SELECT name AS play ,name AS playwright FROM plays INNER JOIN playwrights ON playwrightId = id
There is no way for the database management system to be able to tell the difference between the plays' id and the playwrights' id. To fix this we can do the following.
SELECT
plays.name AS play
,playwrights.name AS playwright
FROM plays
INNER JOIN playwrights
ON plays.playwrightId = playwrights.id
;
(on SQL Fiddle)
By saying which table they come from we are able to use column name and id in the query above. This is a bit wordy which is why we have the AS term. AS allows us to alias the fully name of the table as a different value. Let's look back at the original query.
SELECT
p.name AS play
,w.name AS playwright
FROM plays AS p
INNER JOIN playwrights AS w
ON p.playwrightId = w.id
;
(on SQL Fiddle)
In the above query we have alias plays AS p and playwrights AS w. Now when we go to use the playwrights id we can simply say w.id, likewise p.name is the plays' name column and w.name is the playwrights' name. Notice that we further alias the projections of p.name AS play and w.name AS playwright, this will change the attributes on the result set of the query to play for p.name and playwright for w.name.
Shall bear the business in some other fight,"
-- Shakespeare, Coriolanus
Act I, Scene VI, Lines 81-82
SELECT information on selections
We are finally on the term SELECT. Yep, this is normally the first thing covered when one learns about SQL, but as you now know SELECT is logically the 8th thing that gets looked at when doing a SELECT SQL query.
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE or WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
Projections OR how to impress people when talking about SELECT
A projection is a fancy relational algebra term for something that is very easy to understand. A project can be thought of as a list of things that one wants from a set.
Given the following tables (or data sets):
CREATE TABLE plays (
id [int] IDENTITY(1,1)
,name [varchar](100)
,playwrightId [int]
);
CREATE TABLE playwrights (
id [int] IDENTITY(1,1)
,name [varchar](100)
,birthYear [int]
,birthEra [char](2)
);
We can say I am only interested in the name column (or attribute) of the plays table with the following query.

SELECT name
FROM plays
;
(on SQL Fiddle)
This will limit are results to just the plays in the plays table.
Like wise we can join the two tables together and say which columns (attributes) we want for each.

SELECT
p.name AS play
,w.name AS playwright
FROM plays AS p
INNER JOIN playwrights AS w
ON p.playwrightId = w.id
;
(on SQL Fiddle)
Notice we just do not speak of the things we do not want, SQL is a declarative language (yep, even Forbes think declarative programming is a good thing), this means we describe what we want and not how to do it.
Also notice the AS term, this term allows us to alias things. If we did not have the alias of p and w on the plays and playwrights tables we would not be able to distinguish between the plays' name column and the playwrights' name column or the id on plays and the id on playwrights
SELECT
name AS play
,name AS playwright
FROM plays
INNER JOIN playwrights
ON playwrightId = id
;
(on SQL Fiddle)
We get the following error:
Ambiguous column name 'id'.: SELECT name AS play ,name AS playwright FROM plays INNER JOIN playwrights ON playwrightId = id
There is no way for the database management system to be able to tell the difference between the plays' id and the playwrights' id. To fix this we can do the following.
SELECT
plays.name AS play
,playwrights.name AS playwright
FROM plays
INNER JOIN playwrights
ON plays.playwrightId = playwrights.id
;
(on SQL Fiddle)
By saying which table they come from we are able to use column name and id in the query above. This is a bit wordy which is why we have the AS term. AS allows us to alias the fully name of the table as a different value. Let's look back at the original query.
SELECT
p.name AS play
,w.name AS playwright
FROM plays AS p
INNER JOIN playwrights AS w
ON p.playwrightId = w.id
;
(on SQL Fiddle)
In the above query we have alias plays AS p and playwrights AS w. Now when we go to use the playwrights id we can simply say w.id, likewise p.name is the plays' name column and w.name is the playwrights' name. Notice that we further alias the projections of p.name AS play and w.name AS playwright, this will change the attributes on the result set of the query to play for p.name and playwright for w.name.
Subscribe to:
Posts (Atom)